Research & Learning
Signature Features
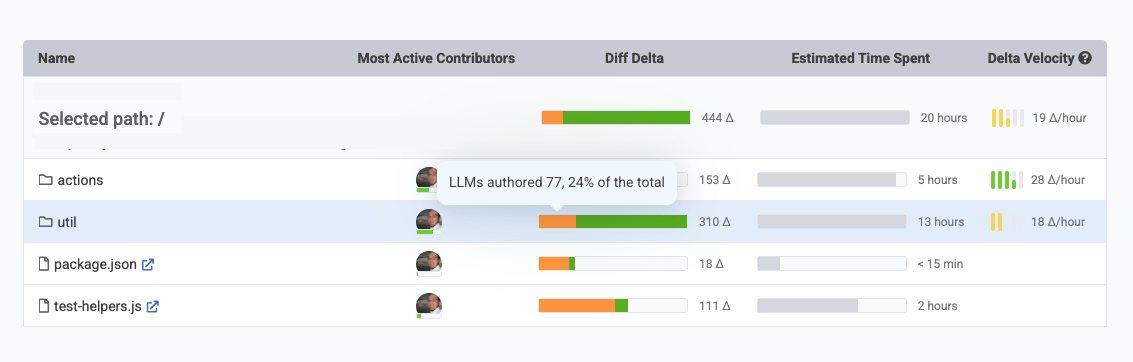
Commit Activity Browser
30% slimmer pull requests
Snap Changelogs: AI-Powered visual change snapshots
Directory Browser
Help Center index
Developer Experience
Top 7 GitClear benefits for devs
30 goals for healthy dev teams
Best software engineering metrics
Developer satisfaction survey tool
Diff Delta™ correlation research
Tech debt: measure and fix it
Manager Corner
Encyclopedia of Dev Analytics
2025-2026 AI Research
Annual performance reviews:
Fast
Popular software engineering metrics, and how they're gamed
All Research & Learning
January 2026 research
:
AI Coding Tools Attract Top Performers - But Do They
Create
Them?
Documentation
Security
Pricing
Blog
Log in
Sign up
We couldn't find the blog post you were looking for. Please check the URL and try again.
Engineering Clarity
The GitClear Blog
Articles
News
Tips
All
June 2026
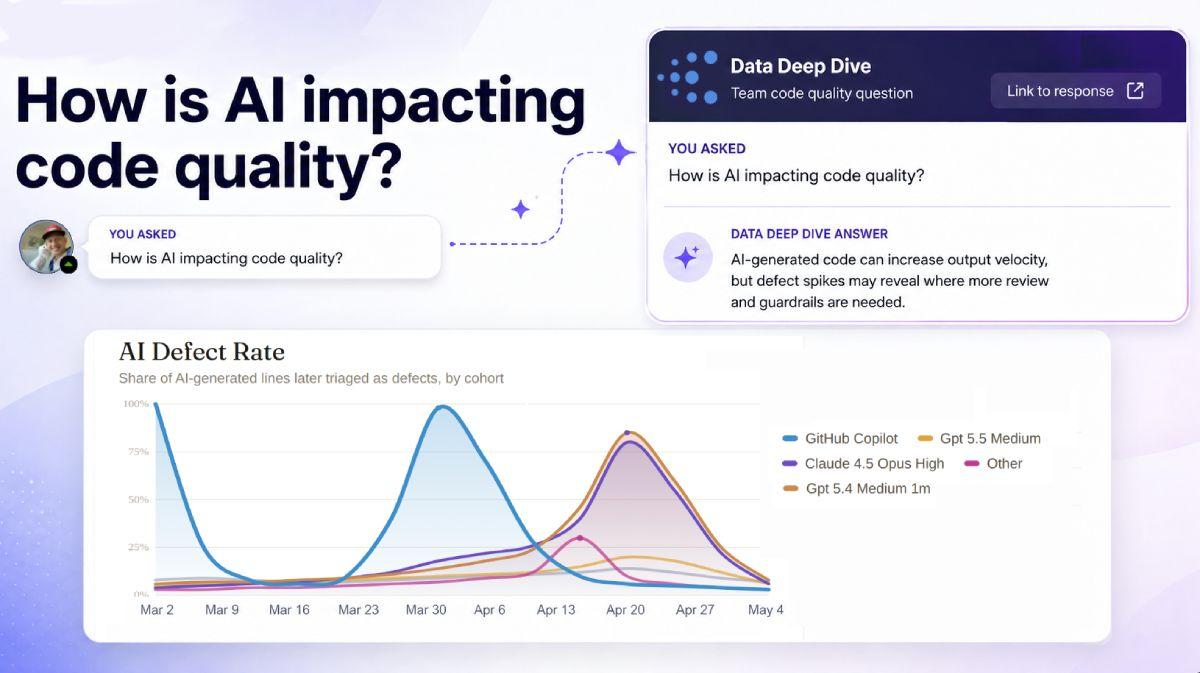
Q2 2026 Updates: A Data Agent That Answers Anything, Claude Telemetry Without Enterprise, and Six Measured AI Providers
April 2026
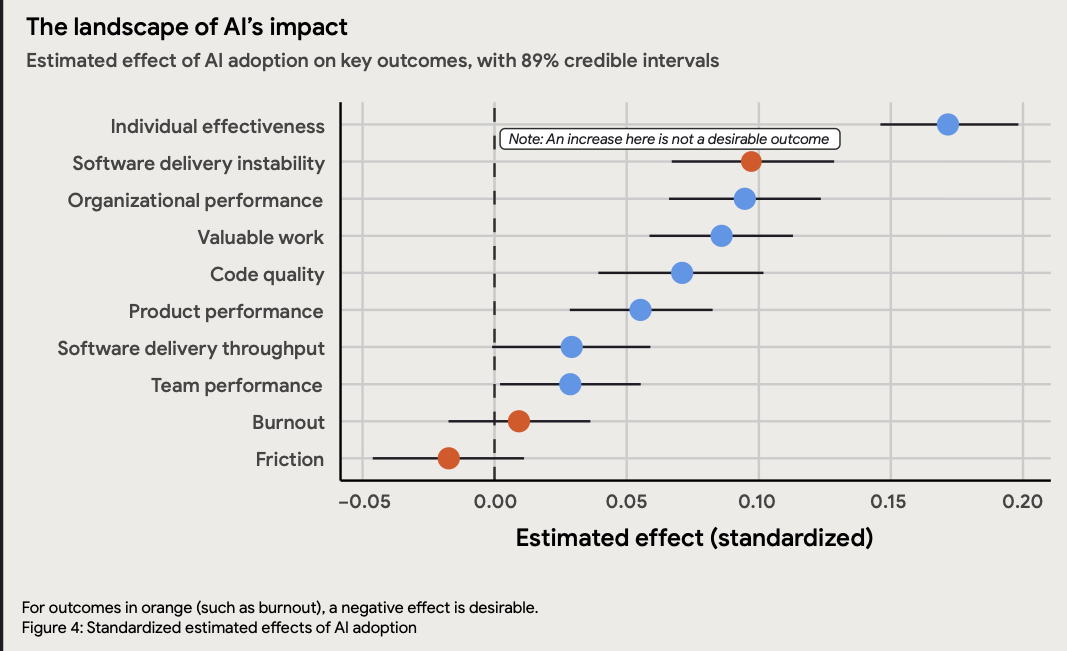
Google DORA AI ROI Research: Summary of 2026 Google Findings
April 2026
What does it mean to measure durable change velocity in the Prompt to Production era?
March 2026
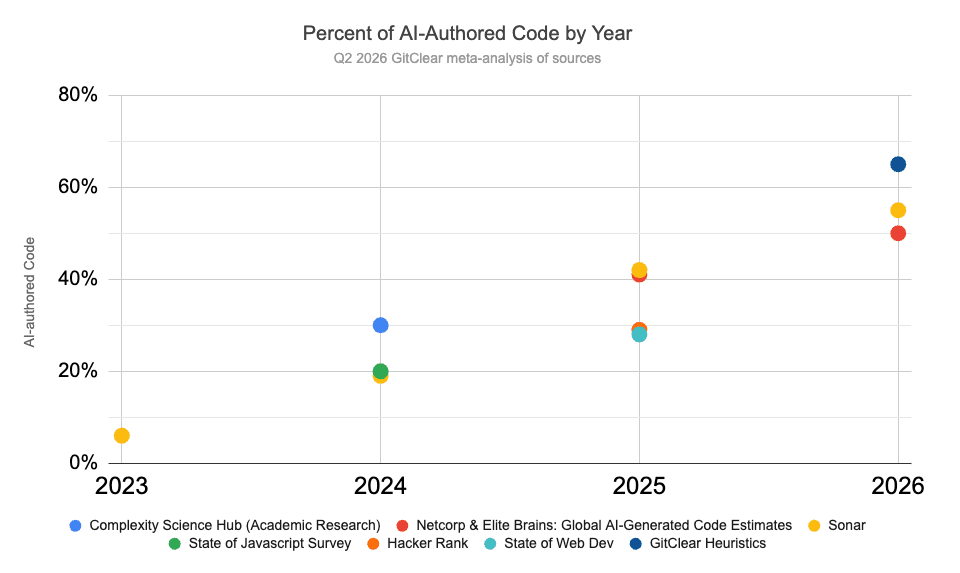
Updates for AI Code Era: Copilot v2 API, Claude, Cursor and Gemini and LLM-Attributed Work
January 2026
Introducing the World Map of Developer Analytic Metrics
January 2026
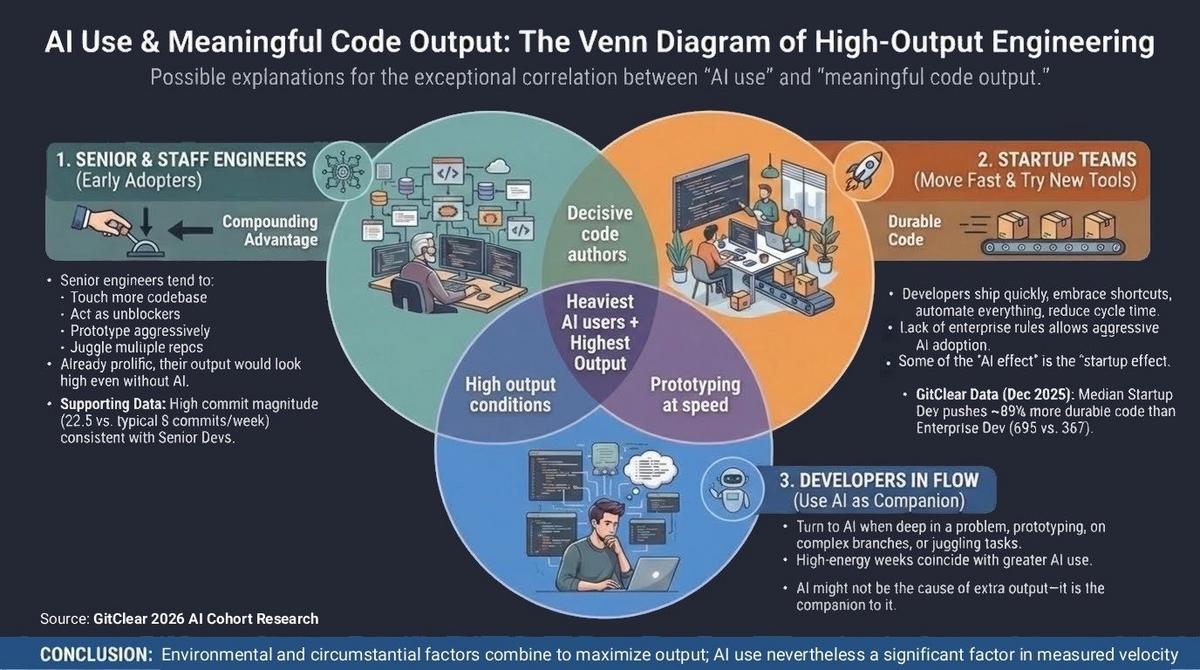
New Research: AI Coding Tools Attract Top Performers – But Do They Create Them?
December 2025
Real world LLM specific examples comparing Claude Opus 4.6 vs ChatGPT 5.4 & Gemini 3 Pro as of 2026
December 2025
Q3/Q4 2025 Updates: Making AI Visible with Cohorts, Context, and a Clearer Path to Engineering Truth
← Previous
1
2
3
4
5
6
7
8
9
10
Next →
GitClear uses cookies to ensure you get the best experience on our website.
Learn more about our cookie policy